Authors:
Most companies have large amounts of valuable data about their clients, products, and processes from which they are not fully benefiting. Machine learning (ML) can help to make sense of this data, finding and learning from patterns in order to uncover insights and support decision making. However, most ML models are black boxes: that is, the model’s complexity makes it difficult for humans to interpret. Due to this lack of transparency, many companies are reluctant to place their trust in ML models and instead continue to rely on more traditional methods, which are often less effective.
As discussed in a previous blog post, Explainable AI refers to the ability to understand and interpret the decisions made by an ML model. By making AI more transparent, Explainable AI can transform ML into a viable option for companies seeking to make data-driven decisions. Explainable AI is not defined by a formal, technical concept. Rather, the term refers to initiatives that respond to ethical and regulatory imperatives to make AI more trustworthy.
In this blog post, we will explore SHAP values, one of the most popular model-agnostic techniques for Explainable AI. As a highly relevant example, we will look at demand forecasting and how SHAP values can make machine learning a practical option that saves time and improves accuracy in one of the most critical supply chain management activities for many companies.
The Demand Forecasting Conundrum
Demand forecasting involves predicting the quantity of goods and services that customers will demand in the future. Crucial for maximizing profitability and mitigating risk through effective supply chain management, demand forecasting is notoriously complex, due to analysis that must account for global markets, economic shifts, technological developments, and more.
Given the quantity of data companies must consider, ML technologies appear to be an ideal fit for these predictive analytic processes. However, the black box problem described above means that many companies continue to use older methods, including more qualitative approaches which can be slower, less accurate, and more prone to human error.

What Are SHAP Values?
SHAP (SHapley Additive exPlanations) values are one of the most popular techniques for Explainable AI that are model-agnostic – meaning that to compute SHAP values, only the input/output of the model is needed; their definition is universal for any model.
Originally introduced by Lloyd Shapley in 1951, the Shapley value is a concept from cooperative game theory used to allocate and explain the contribution of each individual player to the total value gained by all the players. In other words, Shapley values measure how important each player is to the group’s outcome. In machine learning, the analogue of players are model features.
Given a model f(z) with M features, a sample x = (x1, .., xM) and a coalition S (a subset of features), we define the total value of S as the expected value of the model when the values of the features in the coalition are fixed to the values of x and the other values are free. That is, for feature j in S, the model takes zj = xj, and for all other feature indices the model takes random values. E.g., when S is the set of all features then the total value is simply the predicted value f(x), and when S is the empty set then the total value is the expected value of the model E[f]. Mathematically, the total value is expressed as:
fS(x) : = E [f(z) | zS = xS].
The marginal contribution of feature i ∉ S measures the impact of adding i to the coalition, and is defined as
fs∪{i}(x) – fs(x).
To define the SHAP value of feature index i, we first compute the average marginal contribution of feature i over all subsets S of a fixed size s not containing i, and then average over s. This is the contribution of i to the model outcome.
In general (for arbitrary models), an exact computation of SHAP values is often infeasible as the definition requires summing over exponentially many coalitions of features. In practice, SHAP values are usually approximated by sampling random coalitions of features and summing over the marginal contributions for these subsets.
While computing SHAP values in the model-agnostic case is quite expensive, specializing to decision tree models provides some significant performance advantages: it allows for reducing the complexity from being exponential in the number of features to being exponential in the tree depth.
How SHAP Values Can Support Demand Forecasting
The 2022 paper Interpreting direct sales’ demand forecasts using SHAP values, by Mariana Arboleda-Florez and Carlos Castro-Zuluaga, offers a compelling exploration of how SHAP values can support ML in demand forecasting by explaining the results of a CatBoost regression model. We encourage those who are interested to read the paper.
The study looks at a company that directly sells thousands of products to consumers via catalogs. The analysis focuses on apparel items, including sales, marketing, and design data of almost 90 catalogs. The model aims to predict each product’s demand given its features.
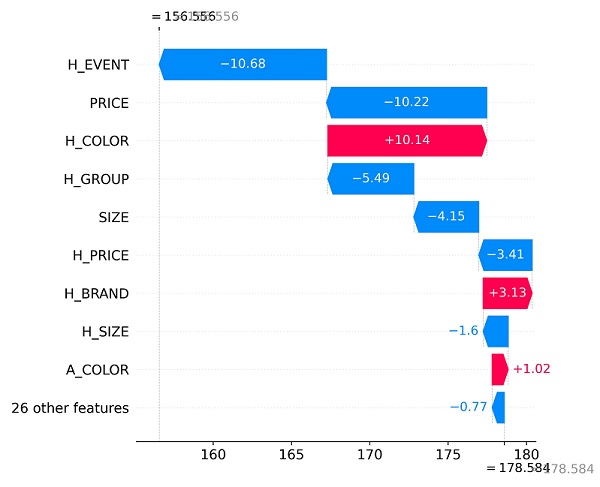
A characteristic and widely appreciated ability of SHAP values is to show both how much and in what way (positive or negative) a given feature affects the prediction. Measuring both magnitude and direction of the effect allows the sum of all contributions to equal the difference between the baseline model output and the current model output, leading to results that are relatively easy to interpret.
In the visualizations included in this paper, one can see, for example, how an event (such as a sale), price, color, size, and more all impact demand in either a positive or negative direction for apparel items. This waterfall plot included in the paper zooms in on the impact of each feature on the model for a single product. The company could use this visualization, for example, to analyze why a new product is predicted to perform poorly.
Conclusion
Given their ability to generate clear explanations while preserving accuracy, SHAP values have large potential to support Explainable AI. By bringing machine learning technologies to the mainstream, SHAP values can enable companies to more fully take advantage of their valuable data.
At Inpher, we have developed XorSHAP, a general purpose privacy-preserving algorithm for computing SHAP values for decision tree models in the semi-honest Secure Multiparty Computation (MPC) setting with full threshold. For more information about SHAP values as part of an ethical and compliant AI strategy, please contact us.