Authors:
As of late the concept of privacy by design has been formalized in data protection laws globally. Having evolved as a way to consider the broader systems and processes in which privacy enhancing technologies (PETs) operate, privacy by design can be further supported by our concept of a privacy budget, which should be allocated in any data-driven project that uses PETs.
In this blog, we explore privacy budget in support of privacy by design for meeting global privacy regulations.
What Is a Privacy Budget?
In a previous blog post, we proposed expanding the concept of the privacy budget. PETs ensure input privacy, enabling computation on sensitive input data without revealing its contents. Yet the result of a computation often allows some conclusions about the input data; and the privacy risk grows with repeated inquiries on the same data. Thus a privacy budget ensures output privacy by restricting the allowed computations on a dataset, keeping the total amount of revealed information within the defined bounds of the “budget.”
What Is Privacy by Design?
Privacy by design aims to provide a universal privacy framework that can apply to information technologies, organizational practices, physical design, or networked information ecosystems. The privacy by design concept originated in the context of developments in PETs in the 1990s. Privacy by design requires organizations to put into place security safeguards and to engineer privacy in all products, services, and their IT infrastructure.
Privacy by design is based on seven foundational principles.
- Proactive not reactive; preventive not remedial
- Privacy as the default setting
- Privacy embedded into design
- Full functionality–positive-sum, not zero-sum
- End-to-end security–full lifecycle protection
- Visibility and transparency–keep it open
- Respect for user privacy–keep it user-centric
Privacy by Design in Privacy Regulations
Privacy by design principles have been incorporated into privacy laws around the world.
The EU General Data Protection Regulation (GDPR) includes data protection by design and data protection by default (the second foundational principle of privacy by design) in Article 25.
In the U.S., privacy by design is required by the Federal Trade Commission (FTC). In its 2012 Protecting Consumer Privacy in an Era of Rapid Change report, it stated as a clear baseline principle that companies should promote consumer privacy throughout their organizations and at every stage of the development of their products and services.
Privacy Budget in Support of Privacy by Design
In the context of the GDPR, the risk of re-identification of personal data that has been anonymized is based on determining if a specific data processing workflow falls within the scope of the GDPR or not. The GDPR does not apply to the processing of data in cases where the data subject is not or is no longer identifiable (see Recital 26 GDPR). Here, the privacy budget can be used as a powerful tool to track the amount of information that gets revealed during a computation or is included in the output.
When the GDPR is applicable, the concept of a privacy budget can help to demonstrate compliance with privacy by design. In a context where organizations must put into place a variety of security safeguards, the privacy budget can be used to better communicate the technical and organizational measures that have been taken to protect privacy under Article 25 GDPR.
In the U.S., the FTC recently warned in a blog post that firms making inaccurate claims about anonymization or secure data aggregation should be on guard as this can be considered a deceptive trade practice that violates the FTC Act. The FTC points out that significant research has shown that “anonymized” data can often be re-identified. Defining and monitoring an overall privacy budget can substantially help to manage the risk of insufficient anonymization of personal data.
Example: Sensitivity
As an example of allocating a privacy budget in support of privacy by design, we will explore one specific metric: sensitivity. The sensitivity of a function or query quantifies the information revealed about the underlying input data. Mathematically speaking, the sensitivity of a function indicates the maximal change of the output value caused by small variations in the input values.
We consider a simplified database (see table below) containing personal information for two individuals who are at least one and at most eighty years of age. The privacy budget allocated here is 4 bits. Before beginning a computation, its impact on the privacy budget is estimated. Only if the privacy budget allows does the computation take place.
If the age of one individual is changed by x years, it will affect the output of the function by x/2 years, or log2(x/2) bits, i.e., at most log2(80/2) =5.32 bits. But if we ask if the average age of a population is greater or equal to 40 years of age, it will affect the output of the function by at most 1 bit. That is, changing the age of one individual is more sensitive than asking if the average age is greater than or equal to 40 years.
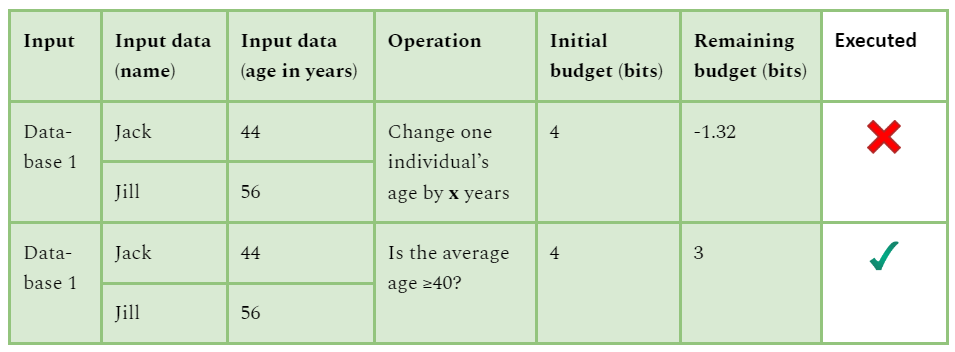
Database with personal information of two individuals, including name and age
In the context of differential privacy, the sensitivity of a function can be used to decide the amount of noise that is added to the final output. If well crafted, this mechanism, combined with a privacy budget, can lead to a system respecting the principles of privacy by design.
Conclusion
Beyond personal data protection, allocating a privacy budget for computations and machine learning (ML) projects is a crucial strategy in preventing data loss in general. Working with sensitive intellectual property data calls for enhanced data loss prevention (DLP) practices. By integrating the concept of a privacy budget into the DLP ecosystem, organizations can strengthen asset management, monitoring, and access controls, leading to improved data breach prevention and risk mitigation associated with data loss.
To further explore this topic, see our white paper Balancing Privacy: Leveraging Privacy Budgets for Privacy-Enhancing Technologies and view our related Web Talk below.