Authors:
Recent developments in machine learning and artificial intelligence have highlighted the benefits data exploration can bring to organizations across industries. These opportunities raise questions around privacy, intellectual property rights, and increased regulations and scrutiny from governing bodies. As a result, the trend of growing support for emerging privacy-enhancing technologies (PETs) has continued to evolve over the past two years.
PETs ensure input privacy, enabling sharing of and computation on sensitive input data without revealing its contents or allowing deduction. However, PETs do not necessarily guarantee output privacy. Revealing the final result of a computation (the output) often allows some conclusions about the input data, which might compromise sensitive data. We propose the broad concept of a privacy budget, which can be combined with most PETs, in order to safeguard output privacy.
Input and Output Privacy
Input privacy
Some prominent examples of emerging PETs include secure multiparty computation (MPC), fully homomorphic encryption (FHE), federated learning (FL), trusted execution environments (TEEs) and differential privacy (DP). By incorporating these technologies, organizations strike a balance between preserving the privacy of sensitive input data and deriving valuable insights from data analysis, including machine learning. To achieve this, PETs employ cryptographic techniques and algorithms (see Nigel Smart’s recent article for an overview of current PETs and how they guarantee input privacy).
Output privacy
Output privacy focuses on measuring and controlling the amount of information leakage in the result of a computation. The Fundamental Law of Information Recovery states that “overly accurate answers to too many questions will destroy privacy in a spectacular way.” This general rule holds true for any technique employed to limit data disclosure: when using PETs, privacy and confidentiality of the input data are not automatically maintained in the output. Instead, with repeated queries on the same data, privacy risk grows in the form of the possibility to recover the information used for the query.
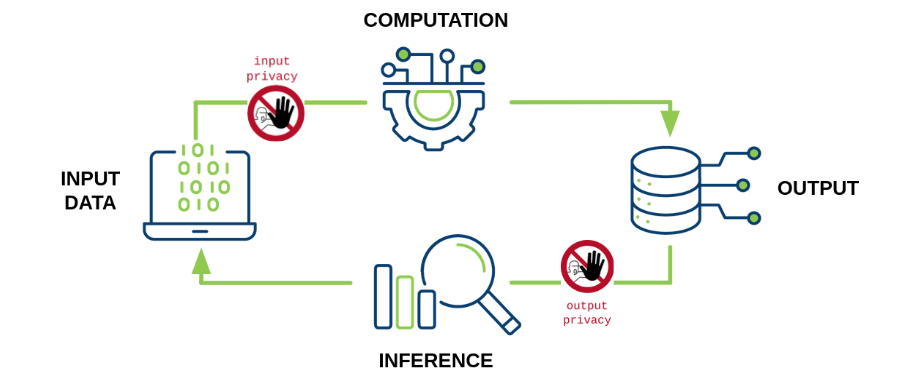
What Is a Privacy Budget?
The purpose of a privacy budget is to define a maximum tolerance for revealing information on input data through the output of a computation. By restricting the allowed computations on a dataset, a privacy budget keeps the total amount of revealed information within acceptable bounds–the “budget.”
The concept of a privacy budget was originally introduced in the context of differential privacy (DP). We propose to expand the concept to be meaningfully applied when using a broad range of PETs.
Example Applications of Privacy Budgets
A privacy budget requires a meaningful privacy metric–a tool to estimate the amount of revealed information for any given computation. In this section, we list example privacy metrics that can be used with various PETs, depending on the specific use case and context.
Query restriction
Suppose an online survey platform is used to collect personal information from respondents, including age, gender, nationality, and education level. To manage privacy while still providing valuable insights, the platform sets a privacy budget to three queries per respondent.
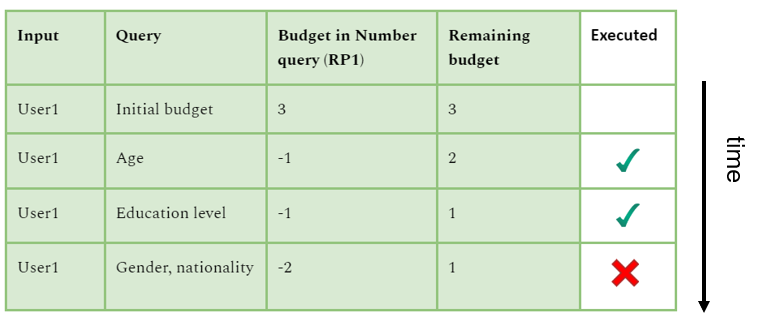
Table 1: Privacy budget table based on number of queries
A limitation of query restriction is that the number and type of authorized queries must be tightly related to the size and the distribution of the input data. For example, querying the gender of an individual in a gender-balanced population might reveal less information than querying for age, but the inverse would be true in a gender-imbalanced and age-balanced population.
Number of bits
Another simple privacy metric is the number of bits that are revealed relative to the size of a data source. In our example, an organization might want to reveal no more than 2% of the total number of bits of a certain dataset. This privacy budget must be tracked across computations.
In a file of 1k rows and 20 columns populated with coefficients of 8 bits, representing 20kB, a privacy budget of 2% allows 3200 bits. A question about averages may expose 8 bits. Asking for colsum (sum of each column) may expose 20(8+log2(1000))=360 bits, and asking for rowsum (sum of each row) may expose around 12322 bits.
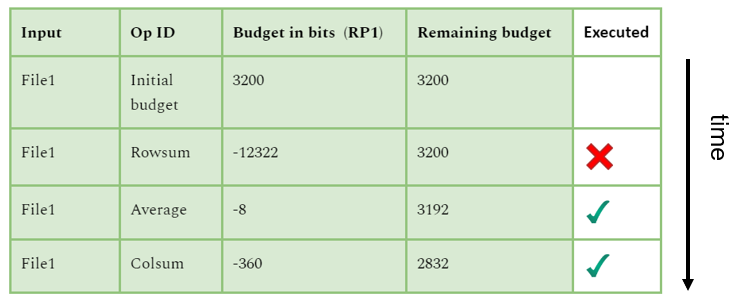
Table 2: Privacy budget table based on number of bits
This measure is easy to compute but overly pessimistic because it does not account for the entropy of the output and dependence on the input.
Finding meaningful (and precise) privacy metrics that are easy to compute for arbitrary algorithms in order to estimate the amount of revealed information is an exciting, ongoing research area. Additional metrics that we will not discuss here include sensitivity, entropy, preimage size, output size, and k-anonymity.
Conclusion
By optimizing the privacy-utility trade off, the concept of a privacy budget allows stakeholders to demonstrate a commitment to privacy protection and transparency while making informed decisions. Understanding and effectively communicating the implications of privacy loss as measured by the privacy budget helps stakeholders correctly manage PET applications while demonstrating compliance with requirements and privacy guarantees in a variety of domains including adtech, healthcare, government, and finance. To further explore this topic, see our white paper Balancing Privacy: Leveraging Privacy Budgets for Privacy-Enhancing Technologies and view our related Web Talk below.