Authors:
Insurance fraud might not seem like the most obvious issue to keep you up at night. Yet according to the U.S. Coalition Against Insurance Fraud (CAIF), 78% of consumers report being worried about insurance fraud. That makes sense. In the U.S., insurance fraud costs insurers $308.6 billion in fraudulent claims; meanwhile, in the U.K., a fraudulent claim is uncovered every five minutes. And consumers are left with higher premiums. We all pay for the crime of insurance fraud.
In this post, we will discuss how new technologies can help in the fight against insurance fraud, and why data – and data privacy – are at the heart of these efforts. But first, we will briefly dig into the current state of insurance fraud.
The State of Insurance Fraud
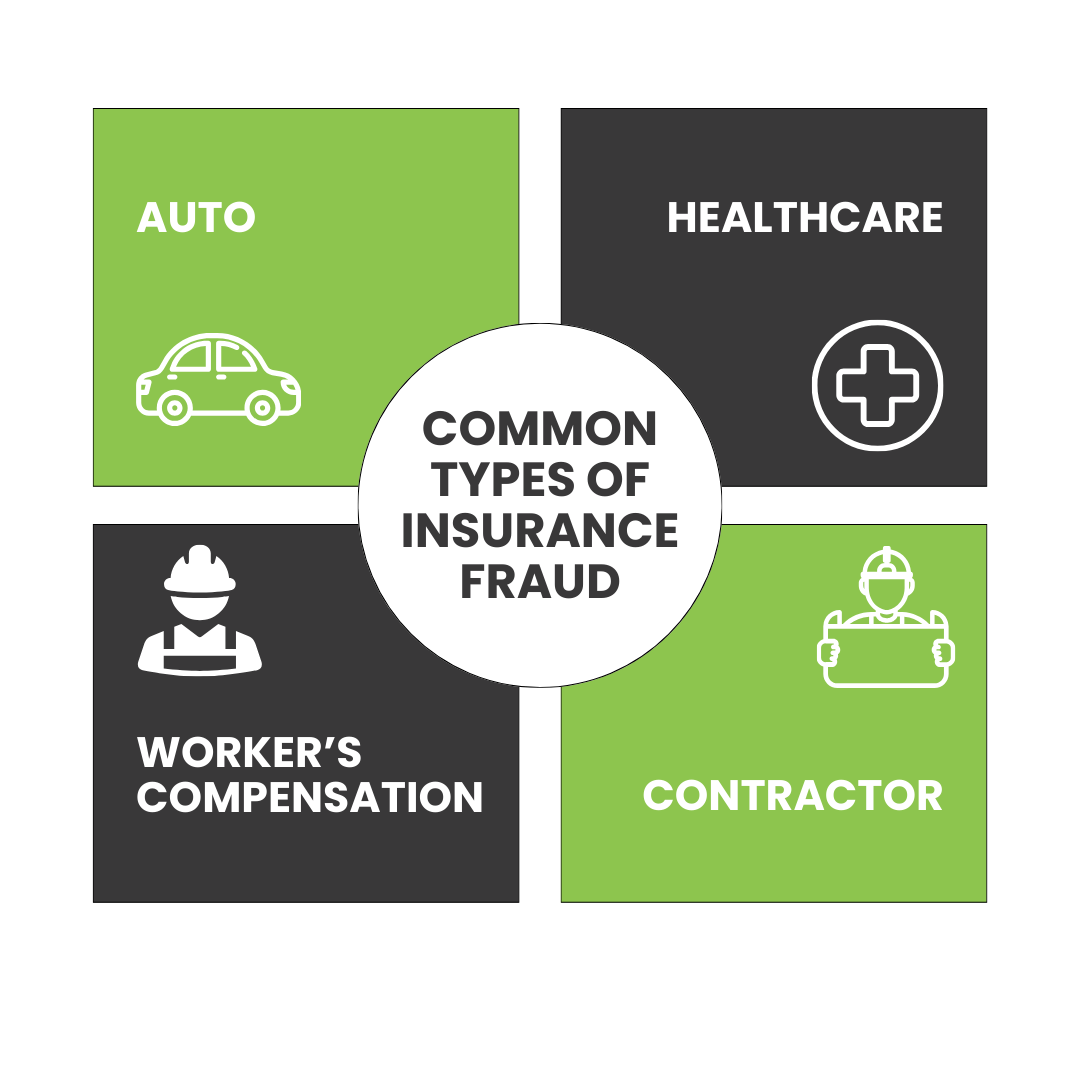 Insurance fraud is a global issue.
Insurance fraud is a global issue.
Recently, the CAIF partnered with IBM and Luxoft on the report Globalization of Insurance Fraud. In their survey of financial crime experts across 30+ countries, 56.8% of experts agreed that their locality does not have dedicated resources to address globalized fraud.
Insurance fraud is becoming more common.
The internet has become the go-to resource for people to get insured, check coverage, and submit claims – making it a gateway for global fraudsters. Ease of doing business helps us all, but it is also a means for bad actors looking to kick off another scam. It’s not surprising, then, that losses from insurance fraud have nearly doubled in the past few decades.
Insurance fraud is growing in complexity.
Fraud plots often involve multiple industries: CAIF reports that 84% of insurance organizations say the cases they investigate cross industries; for example, an insurance investigation could uncover financial fraud as well.
Fighting Fraud with AI
With all types of fraud, it takes a programmatic networked approach to defeat a system – and the same rule applies to insurance fraud. In the insurance industry, advanced technologies are critical for improving operational efficiency, providing excellent customer service, and ultimately increasing the bottom line.
In the above-mentioned survey from CAIF, IBM and Luxoft, AI and data analytics emerged as the most beneficial technologies for addressing global insurance fraud. With AI, insurance companies can analyze their large, varied, and complex datasets to extract the insights they need. Nearly 60% of insurers are currently leveraging AI to fight fraud (a large number, though that leaves over 40% who are not).
For example, machine learning (ML) models trained with historical data can identify patterns to quickly detect abnormal or unexpected activity. This enables insurers to investigate and correctly identify a suspicious applicant or fraudulent claim. In the last decade, third-party developers like Friss, Shift Technology and IBM have begun offering ML systems to insurance companies. A combination of technologies including ML can effectively deliver predictive analytics and investigative learnings to establish fraud and claim legitimacy.
The Collaboration Imperative
More data means more insights. ML models need large volumes of data to be trained and improve over time. Concerns about data quality, lack of data and model bias are some of the key barriers for insurance companies to employ AI. A single insurance company may not have enough data to build an optimal fraud detection model. Increasingly, insurers are recognizing that data collaboration with ecosystem partners is crucial.
For example, in the life insurance industry, the MIB Data Vault, established in 2020, includes data from nine carriers, with close to 20 million records. Those nine insurers have reported benefits in detecting breach violations before claims time, when it might be too late.
The data vault is also intended to help in identifying omissions and fraudulent activity on the front end, before the customer has purchased life insurance. Insurers receive automatic alerts about potential non-disclosure, misrepresentation, and fraudulent intent, and can view irregular application patterns by consumers or agents.
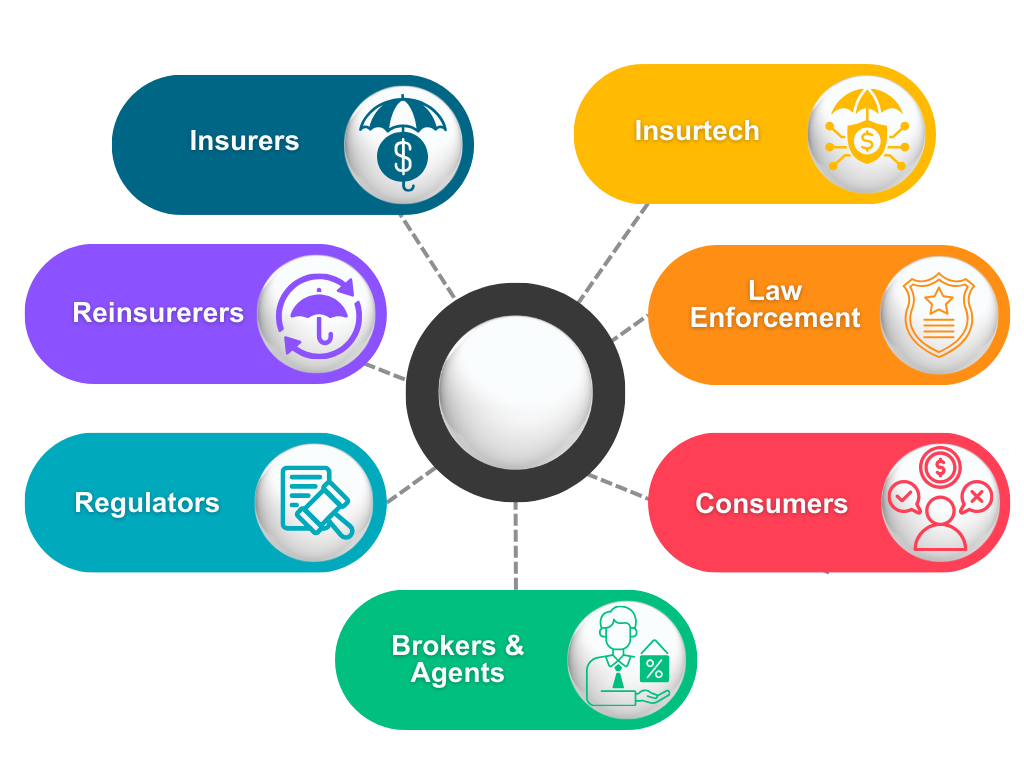
Data sources throughout the insurance ecosystem.
Barriers to Data Collaboration
Despite the obvious benefits, many insurance companies are hesitant to collaborate due to privacy concerns. Insurance companies hold extensive, sensitive information about their customers:
- Personally identifiable information (PII)
- Credit scores
- Health records
- Property details
- Financial records
- And much more
Insurance companies must comply with privacy regulations such as GDPR in the EU or CCPA in California. In addition, they need to maintain trust among customers who have entrusted them with sensitive data. Further, some companies fear losing their competitive edge by sharing business information. As a result, data collaboration is still circumscribed. According to a recent analysis by Friss, at this time insurers are mostly sharing limited information about claim history and fraud cases. Secure collaboration between the public and private sector could also help in the fight against insurance fraud, yet remains stunted.
The CAIF/IBM/Luxoft report notes that the biggest obstacle to fighting global insurance fraud is “consumer data privacy regulatory restrictions” as well as “other concerns around customer data being shared with others to help mitigate fraud.”
Privacy-Preserving Fraud Detection
To address these issues, advanced AI analytics can be paired with advanced privacy-preserving technologies.
For example, privacy-enhancing technologies (PETs), such as Secure Multiparty Collaboration, support data collaboration for Data Analytics and Machine Learning. PETs enable secure, privacy-preserving computations, in which the collaborating parties do not need to share data or expose their data to each other.
Privacy-preserving insurance fraud solutions solve privacy and collaboration issues by:
- Enabling computations on private data
- Securing data at scale
- Providing the proper support for computing confidential data across organizations
- Improving fraud detection processes
- Increasing customer trust in onboarding and approval processes
- Creating new opportunities to cross-reference the right data in the event of suspicious activity
All these benefits, individually and together, help address the vast risks facing insurance agencies today – and make companies’ portfolios healthier in the face of potential fraudsters.
To learn about Inpher’s privacy-preserving solutions, visit our website.