Authors:
In the second part of our Inpher XOR DataFrame API blog series, we will show an example how crossrequest caching avoids computing results several times. We will also discuss the steps and components of the XOR Platform involved when executing a DataFrame program.
Let’s continue with our manufacturing process monitoring example introduced in part 1 of our series. Rose, our Quality Engineer, wants to build a linear regression model to detect when a critical dimension of the produced items (e.g the diameter) is drifting from the target value (see the code snippet below).
- Rose selects the sensor dataset from blog post 1, which contains the independent variables X. She then vertically stacks the metrology datasets from each factory containing the measurement to be predicted, i.e. the dependent variable y.
- The metrology and sensor datasets are joined on the run_id column to only keep rows present in both datasets.
- Rose creates the training and test datasets for linear regression.
- Trains a linear regression model, and asks for the execution of the Dataframe to print out the model weights.
- She evaluates the performance of the model by computing the rss, mae and r2 scores on the test dataset, and again triggers an execution of the DataFrame.
- Closes the session. All the intermediary (i.e internal) results are deleted.
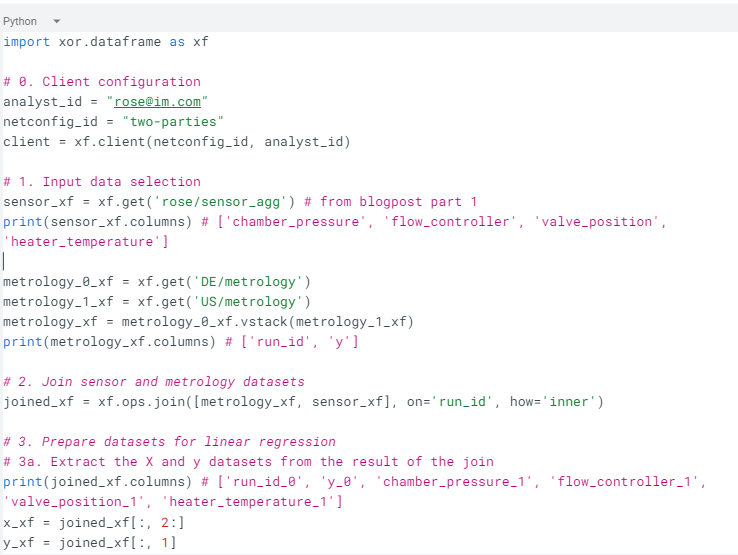

Fig 1 below shows the XOR DataFrame graph corresponding to the code snippet above. The nodes represent operations and the arrows indicate input dependencies. For instance, to evaluate the train_test_split operation, one must first evaluate the join operation. We highlighted in yellow the steps where the analyst Rose requested an execution of the DataFrame graph built so far. Thanks to cross-request caching, when executing the regression_metrics operation, the fit, train_test_split, and join operations are not recomputed, reducing the compute time by 2.
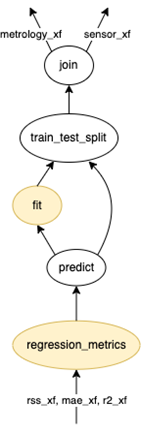
Fig 1. XOR DataFrame compute graph
Behind the Scenes
Let’s have a look at what happens on the backend when Rose runs a DataFrame program. As shown in Fig 2 below, 4 components are involved in the processing of a request.
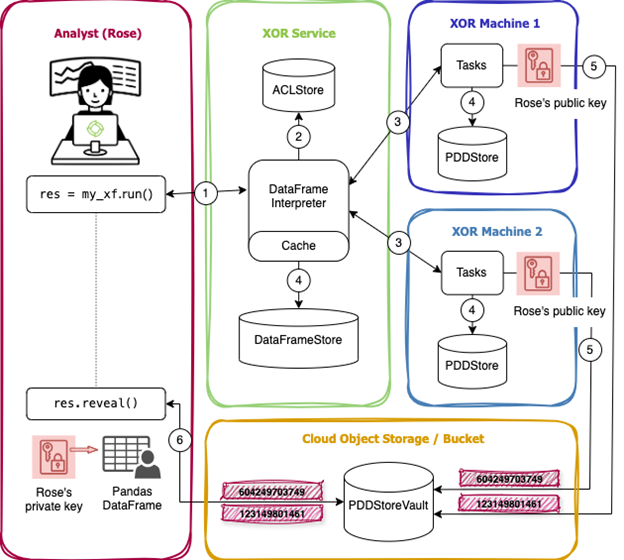
Fig 2. XOR DataFrame Computation Flow
Analyst Environment
This is the machine on which Rose has installed the XOR DataFrame library and is doing development.
XOR Service
When receiving a request from an analyst to execute or reveal a DataFrame (1), the XOR Service first checks if all the data admins of the input datasets have authorized the computation using an Access Control Lists (ACL) mechanism (2); more on this topic in blog post 4. It then interprets the DataFrame into one or several execution graphs, composed of plaintext and multi party computations, and orchestrates them into the XOR Machines as tasks (3). We will provide examples of execution graphs in blog post 3. If the part or the whole DataFrame was already computed, the result is retrieved from the cache and returned to the analyst and not computed again.
XOR Machine
The actual execution of a computation happens on the XOR Machines, where the data sources are physically stored. Upon completion of a task scheduled by the XOR Service, a XOR Machine persists the results in a local storage called the PDDStore, and returns a reference to the XOR Service to be put in the DataFrameStore for further usage (4).
When processing a reveal task, each XOR Machine encrypts its share of the secret-share dataset to be exported with the recipient’s public key and sends it to the PDDStoreVault (5).
PDDStoreVault
The PDDStoreVault is a cloud object storage that allows to export a dataset for a recipient (here Rose) or ingest datasets into the XOR Platform. To reconstruct a secret-share dataset in plaintext, the XOR DataFrame library downloads each share of the target dataset, decrypts, and recombines them into a Pandas DataFrame (6). The PDDStoreVault is a read-once datastore, datasets are deleted after they have been fetched.
Conclusion
By avoiding unnecessary computations, caching increases the efficiency of DataFrame programs and reduces resource utilization. From the privacy aspect, the encryption of the exported shares in the PDDStoreVault ensures that only the final recipient can see the result in plaintext. Moreover the ACL mechanism guarantees that only computations that are explicitly authorized by data admins are executed.