Authors:
Inpher’s XOR Platform delivers enterprise-ready data science capabilities to develop, test, integrate and deploy cryptographically secure workflows. We are excited to make generally available to all our customers the DataFrame API, which is a new way for data analysts to select input datasets, chain operations, and run them on the XOR Platform with a syntax close to Pandas DataFrames. This new API offers a leaner interface that is more intuitive to use.
In this post, we will give an overview of some of the key benefits of the DataFrame API and provide a code example of how one can analyze the assembly lines of two factories. A subsequent post will show how computation requests are processed in the backend and go over cross-request caching using a more complex example. In the third post we will talk about execution graphs and early validation. The last post of this series will cover how data admins can define use policies of their datasets using ACL.
Key Benefits
User friendly
The XOR DataFrame API offers a level of abstraction that creates an experience similar to a plaintext library, allowing users to focus on their analytical goals with data privacy and security assurance. As we will explore further in this post, XOR DataFrames programs tend to be simple and succinct.
Powerful
The API supports inputs that are a mix of plaintext and secret-share (formatted for Secure Multiparty Computation, or MPC) data from various sources or locations. As we will explore in a subsequent blog post, the same DataFrame function can be interpreted into very different execution plans, depending on the data locality and visibility. The optimal execution steps are determined on the backend and are transparent to the user.
Versatile
In creating this API, we have responded to customer requests to support SQL like operations, such as groupby, join and filter. We added to the backend the possibility to combine local plaintext computations with MPCs, broadening the functions that can be implemented and added to our library. As a prime example, our Fuzzy Matching algorithm extensively uses this new capability.
What are XOR DataFrames?
A XOR DataFrame represents a stacking (vertical or horizontal) of data from different sources that reside with one or many participants in a privacy-preserving computation. It allows an analyst to abstract away the visibility (plaintext or secret-share) and location of the data when writing data workflows. It can also be seen as a virtual tabular dataset with named columns (i.e., headers) of potentially different types (int, float, boolean and string). By virtual, we mean that only the headers, types and dimensions (i.e., metadata) are accessible to the analyst. The value of each cell is not visible.
Example:
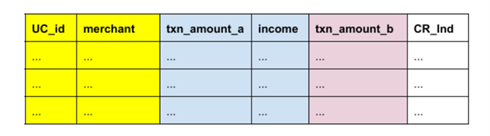
The above XOR DataFrame has 6 columns and 3 rows. Its header is written above. Assuming we have two players in this scenario, we use colors to represent the visibility and location of the data:
- Yellow for plaintext data owned by all players, columns UC_id and merchant
- Blue for plaintext data owned by player 1, columns txn_amount_a and income
- Purple for plaintext data owned by player 2, column txn_amount_b
- White for secret-shared data between all players, column CR_Ind
This is one of the many possible DataFrames that can be built.
Code Example – Analyze Assembly Lines
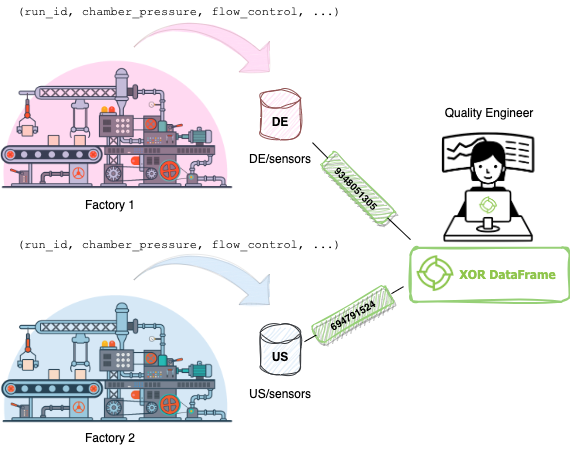
As illustrated below, let’s take the example of Rose, a Quality Engineer working at the headquarters of IntelligentManufacturing Inc. Rose wants to perform data analytics on the assembly lines of two subsidiary companies using the XOR Platform. The factories are located in different countries, one in the U.S. and one in Germany. They are manufacturing the same items and have the same production process, which is monitored end to end.
As the data collected by the two factories have the same schema (i.e columns), Rose can vertically stack them, and run secure computations on the stacked dataset. The private plaintext data never leaves the database of the factories; only random numbers transit over encrypted channels during a computation.
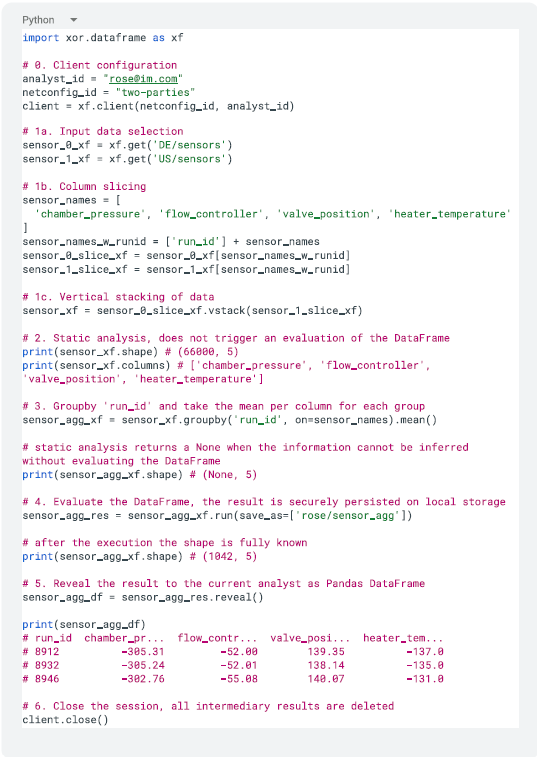
The snippet below shows how Rose uses the DataFrame API to perform a groupby().mean() operation. After initiating a client() with a netconfig_id which specifies the involved parties, i.e., the 2 factories
- Rose selects the datasets from each party with xf.get(), and specifies the columns to keep using the standard Python slicing syntax. She then vertically stacks the two datasets together to create a new XOR DataFrame (sensor_xf). Note that we use the _xf suffix to indicate a XOR DataFrame object.
- The XOR DataFrame is a lazy API: a DataFrame is evaluated only when the run() method is called. It is, however, possible to do a static analysis of a DataFrame without triggering a (secret) computation to get its dimensions, column names and types. These metadata are public information, i.e., visible to all. In the snippet, Rose prints the dimensions of the stacked DataFrame using the .shape attribute and the column names with .columns. Static analysis works by propagating the inputs’ metadata through the graph of operations to the outputs.
- Rose specifies the operations to be computed. She groups samples with the same ‘run_id’ (i.e., type of product) together and takes the mean per column (i.e., sensor name). For some operations, such as groupby, the number of rows or columns of the output are data dependent and cannot be known without evaluation. We use None to indicate unknown static information.
- Rose requests the execution of the DataFrame using the .run() method. The result of the aggregation is saved securely on the local storage of each party. It can later be used as input to other operations. As you can see after the evaluation, the number of rows of the result becomes known. The next blog post will provide insights into the system architecture and execution flow.
- To print the result, Rose needs to reveal it to herself. This action fetches the encrypted secret-shares from all the parties and reconstructs the plaintext data into a Pandas DataFrame. This is of course a dangerous operation that should be authorized with caution. In our last blog, we will see how data admins can allow a DataFrame to be revealed with ACLs.
- Close the session. All the intermediary (i.e internal) results used for caching are deleted from the backend storages. In the next blog post we will illustrate with an example the value of cross-request caching. If the session is not closed, intermediary DataFrames are deleted after their time-to-live (24 hours by default).
Conclusion
Writing privacy-preserving programs using the XOR DataFrame API is both intuitive and straightforward. By removing the complexities inherent to the distributive nature of the datasets and hiding the cryptographic techniques used to guarantee data privacy, the API gives the analyst the impression of working with data from a single source. This enables the analyst to focus on solving their business problem.
Read part 2 of our series: Inpher XOR DataFrame API – Caching and Computation Flow