Authors:
This blog post was jointly written by Dr. Marc Desgroseilliers (Senior Statistics Engineer), Abson Sae-Tang (Director of Engineering) and Dr. Dimitar Jetchev (Co-Founder and CTO)
TL;DR
Inpher’s team has built XORBoost, an algorithm that enables training an XGBoost model collaboratively on encrypted data. For ease of use, XORBoost follows an API similar to XGBoost’s sklearn python API, but with security integrated, making it easier for data scientists to leverage sensitive data for building models. XORBoost is part of Inpher’s XOR Platform that enables algorithms for privacy-preserving machine learning.
XORBoost facilitates the development of secure and collaborative tree boosting models using Secure Multi-Party Computation (MPC). MPC is an advanced cryptographic technique where multiple data owners can jointly build models with more features and/or more data without exposing or moving their data. We illustrate this through a notebook example on credit card fraud detection where two banks collaboratively build a model. Data scientists can try this (and several other use cases) today on our XOR™ Trial Beta Platform.
Introduction
Organizations are constantly seeking ways to leverage large quantities of data to build better and more accurate ML models. Data is often stored across teams, geographical locations, or organizations. Concerns around trust, privacy and compliance can make it difficult to share data which leads to barriers to innovation.
Secure collaborative learning with MPC addresses these issues, allowing many data owners to build models on their collective data without revealing their private datasets. For example, banks can collaborate on anti-money laundering efforts while keeping their customer data private. Likewise, healthcare providers can pool their patient data with pharmaceutical companies for medical studies.
In this blog post, we present XORBoost, a new privacy-preserving implementation of the popular XGBoost method, and share how it works. Additionally, the article walks through a notebook example related to a classification problem in credit card fraud detection where two banks collaborate by secret sharing their data. For the notebook, we are using a public dataset from Kaggle. This use case is similar to BNY Mellon’s use of Inpher’s technology for fraud detection. BNY Mellon is one of the largest custodian banks overseeing more than $41.1T of custodial assets and 6.8M wire transactions processed per month. Based on the preliminary use of XORBoost, BNY Mellon was able to build a fraud detection model by using collaborative data that was 20% more accurate than their internal data alone.
An Overview of Gradient Tree Boosting
Extreme Gradient Boosting, or XGBoost, is an open-source library for gradient tree boosting. The latter is a machine learning technique that outputs a decision tree ensemble model (i.e. a set of distinct decision tree estimators pooled together to make better predictions) for either regression or classification problems. Decision tree ensembles provide accurate models for various applications, including binary classification problems with small positive class ratio. This is typical of fraud detection applications: the number of fraudulent transactions is several orders of magnitude smaller than the number of legitimate transactions. Logistic regression typically struggles in these situations.
The boosting technique constructs an ensemble model and avoids making statistical assumptions on the data. Moreover, a trained gradient tree boosting model provides the information to infer how useful each feature was in training the model. This gives the ability to order the features according to their importance and therefore provides good explainability and auditability. The idea behind boosting boils down to fitting a (typically weak) estimator, computing the residuals and then fitting a new estimator to these residuals. This procedure is repeated and every new estimator is added to the ensemble. Gradient tree boosting uses decision trees as the weak learner. Every internal node of a given decision tree corresponds to a split feature and a split value. For example, all instances of a feature referencing an age under thirty (age <= 30) should be considered in the left subtree and all instances with an age over thirty (age > 30) should be considered in the right subtree. These split features/values (age values greater or less than thirty) are chosen to maximize the loss reduction in a gradient descent step. For more details, we refer the reader to the original XGBoost paper.
Gradient tree boosting has many advantages:
-
It is flexible; making the next estimator fit the residuals, it adapts to the data and attempts to correct in regions where the previous fit was poor.
-
It does not make assumptions on the data distribution.
-
It can handle missing values in a principled way without resorting to numerical imputation. This means that the data scientist can use this model right away, without choosing an imputation method for the missing values.
-
It can adapt to different loss functions and can therefore handle both classification and regression problems.
While its benefits to the data scientist are significant, gradient tree boosting can also be computationally intensive as it can require a large number of trees to give good results.
XORBoost: Privacy-Preserving XGBoost, Done Right
There are many implementations of gradient tree boosting such as CatBoost, LightGBM or XGBoost, each with their own specificities. XORBoost is a privacy-preserving variant of XGBoost. Indeed, the constraints of MPC computations lead to different tradeoffs and optimizations required to obtain a high performance algorithm that scales to large datasets. See Inpher’s XORBoost paper for more details on the implementation.
XORBoost is inherently privacy-preserving; it trains a gradient tree boosting model without revealing any information about the initial datasets or any intermediate computation step. No compromise is made when training a XORBoost model: every intermediate data structure remains fully opaque to all parties. This model can then be used to make predictions for new data not seen during training. The predictions for new data can be kept secret though they will typically be revealed to all players involved in the computation as this is the final output all parties are interested in obtaining at the end of the MPC process.
Moreover, XORBoost works for all data distribution scenarios; it works if the data is horizontally split amongst the players (every player has complete rows of the dataset), vertically split amongst the players (every player has complete columns) or any combination of the two.
A deployment of XORBoost consists of the following entities [See the figure below]:
-
A front-end portal where data scientists or analysts can use the XOR UI, Python Notebooks or the REST API to build and deploy models.
-
Privacy Zones, where multiple data owners wish to train a model on their individual data collaboratively. From XOR’s perspective, each data owner is considered a privacy zone.
-
XOR Machine(s), a virtual machine or container in a privacy zone where local computations with the secret-shared datasets are run.
-
XOR Service, a cloud-based service that hosts the XOR Platform.
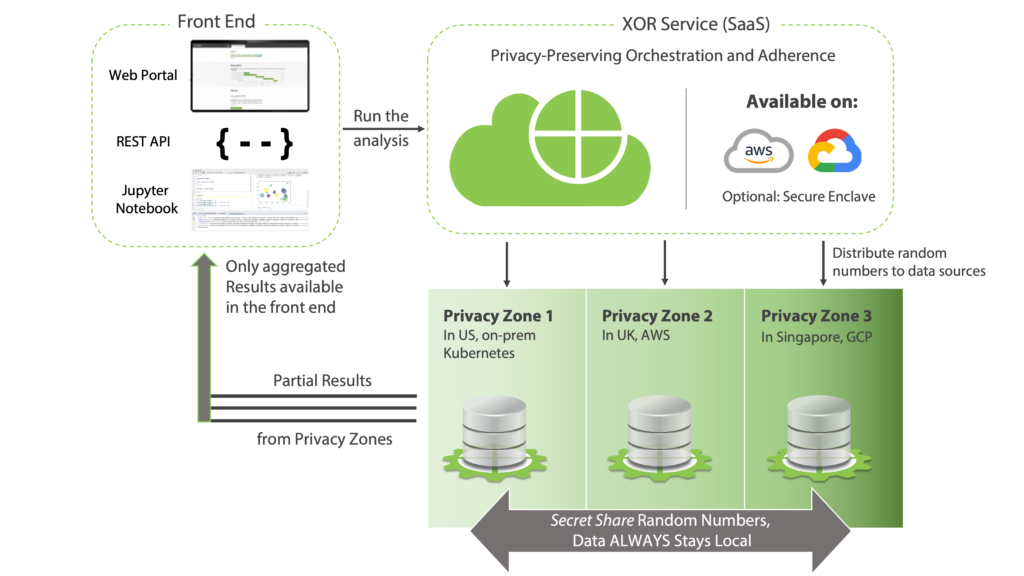
Once users interested in analyzing data with XORBoost have installed the above components, the process of MPC operates in the following order:
-
Specifying Computation:
Data scientists create a python notebook with the XORBoost algorithm and the relevant datasets that should be used for the computation. (In the next section, we illustrate this with a fraud detection use case). Once created, the python notebook sends instructions to the XOR Service hosted on AWS or GCP.
-
Compilation & Random Number Generation:
The XOR Service compiles the MPC-aware algorithm and sends the compiled executable to the XOR Machines in each of the local privacy zones. Additionally, it sends random numbers required for masking the input data in MPC protocol and distributes those to the data sources.
-
Secret Computing:
The XOR Machines then execute the XORBoost algorithm with their local dataset. When information must be exchanged, it is masked using the random numbers made available by the XOR Service.
-
Result Aggregation:
XOR Machines generate partial results of the computation. These are then pooled together to reconstruct the final result and reveal it to the front end.
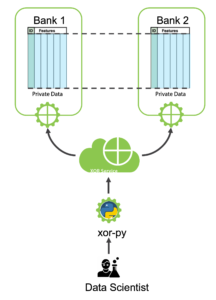
Demo Notebook: Credit Card Fraud Detection
The purpose of this notebook is to give a practical example of using XORBoost for credit card fraud detection. Here two banks, who cannot share their data due to privacy or regulatory reasons train a better model by leveraging all the data available.
We begin by setting the parameters for XORBoost. For more information about the meaning of these parameters, refer to Inpher’s developer documentation. The parameter’s names follow their XGBoost equivalent.
model_params = {
‘n_trees’: 50, # Number of trees
‘tree_depth’: 6, # Tree depth
‘n_buckets’: 128, # Number of buckets for the discretization
‘lam’: 2, # Regularization parameter
‘eta’: 0.3, # Learning rate
‘gamma’: 0, # Minimum loss reduction
}
# Last column, holding the target vector y, for convenience
last_col = 29
# Max RAM allocated to model training
ram_gb = 4
We refer to the user of the notebook as the analyst. The analyst might be different from the players involved in the computation. She uses the xor-py python library to send computation instructions that will then be compiled into MPC programs to be executed by the XOR Engine.
The datasets are already present on the two players’ respective XOR Machines. As this is a standard setup, she uses a preset `two-parties` network configuration with player-0 and player-1.
from xor import session
from xor import operation as op
netconfig_id = ‘two-parties’
sess = session.open_session(xor_service_url, xor_service_port, api_token=auth_token)
We start by fitting the model. Note that all intermediary datasets are secret shared and thus no information about them is revealed.
# Initiate a new computation
comp = sess.new_computation(netconfig_id)
# Select players’ train datasets and stack them vertically
p0_train = comp.use_private_dataset(‘player-0’, ‘creditcard_fraud_small_train_p0’)
p1_train = comp.use_private_dataset(‘player-1’, ‘creditcard_fraud_small_train_p1’)
x_train = p0_train[:, :last_col].vstack(p1_train[:, :last_col])
y_train = p0_train[:, last_col].vstack(p1_train[:, last_col])
# Select XORBoost classification training operation
comp.select_operation(
op.XorboostClassification(
input_x=x_train,
target_y=y_train,
input_xohe=[],
n_trees=model_params[‘n_trees’],
tree_depth=model_params[‘tree_depth’],
n_buckets=model_params[‘n_buckets’],
lam=model_params[‘lam’],
gamma=model_params[‘gamma’],
eta=model_params[‘eta’],
contains_nan=False,
available_ram=ram_gb
))
# Request the computation to start and observe its progress
xorboost_model = comp.run()
Once the model training is complete, we can now run the prediction phase. The information related to the trained model was exported during the training phase. These are the threshold values, the feature_selectors (for each split, which feature should be considered) and the weights for the leaves of each tree. There is also an initial value to start the training procedure: this could be 0, or the average of the response variable y. These datasets constitute the model and need to be imported by the predict function. Their names can be found in the developer documentation.
# Initiate a new computation
comp = sess.new_computation(netconfig_id)
# Build x_test feature matrix by stacking players’ test datasets vertically
p0_test = comp.use_private_dataset(‘player-0’, ‘creditcard_fraud_small_test_p0’)
p1_test = comp.use_private_dataset(‘player-1’, ‘creditcard_fraud_small_test_p1’)
x_test = p0_test[:, :last_col].vstack(p1_test[:, :last_col])
# Select the previously trained model
thresholds = comp.use(xorboost_model[‘xgbThresholds’])
feature_selectors = comp.use(xorboost_model[‘xgbThresholds’]
weights = comp.use(xorboost_model[‘xgbWeights’]
y_hat_init_value = comp.use(xorboost_model[‘xgbYHatInitValue’]
# Select XORBoost classification prediction operation
comp.select_operation(
op.XorboostClassificationPrediction(
input_x=x_test,
input_xohe=[],
input_thresholds=thresholds,
input_feature_selectors=feature_selectors,
input_weights=weights,
input_y_hat_init_value=y_hat_init_value,
input_ohe_permtuation_matrices=[],
eta=model_params[‘eta’],
tree_depth=model_params[‘tree_depth’],
n_buckets=model_params[‘n_buckets’],
n_trees=model_params[‘n_trees’]
)
)
# Request the computation to start and observe its progress
xorboost_pred = comp.run()
We can now compute the confusion matrix for the predicted classes as well as the AUC. We decide to reveal these.
# Initiate a new computation
comp = sess.new_computation(netconfig_id)
# Build y_test target vector by stacking players’ test datasets vertically
p0_test = comp.use_private_dataset(‘player-0’, ‘creditcard_fraud_small_test_p0’)
p1_test = comp.use_private_dataset(‘player-1’, ‘creditcard_fraud_small_test_p1’)
y_test = p0_test[:, last_col].vstack(p1_test[:, last_col])
# Select the previously predicted classes
pred_classes = comp.use(xorboost_pred[‘predClasses’])
# Select confusion matrix operation
comp.select_operation(
op.ConfusionMatrix(y_test, pred_classes)
)
# Export result to analyst
comp.export_analyst()
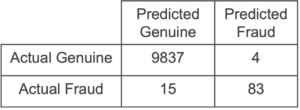
confusion_matrix = comp.run()
The resulting confusion matrix is
We compare this to the confusion matrix obtained from the plaintext XGBoost library with the same parameters:
# XGBoost Scikit-Learn API
from xgboost import XGBClassifier
xgb_model = XGBClassifier(
n_estimators=50, max_depth=6, eta=0.3, reg_lambda=2,
objective=‘reg:logistic’, booster=‘gbtree’, tree_method=‘hist’
)

# Initiate a new computation
comp = sess.new_computation(netconfig_id)
# Build y_test target vector by stacking players’ test datasets vertically
p0_test = comp.use_private_dataset(‘player-0’, ‘creditcard_fraud_small_test_p0’)
p1_test = comp.use_private_dataset(‘player-1’, ‘creditcard_fraud_small_test_p1’)
y_test = p0_test[:, last_col].vstack(p1_test[:, last_col])
# Select the previously predicted probabilities
pred_probs = comp.use(xorboost_pred[‘predProbs’])
# Select AUC operation
comp.select_operation(op.Auc(y_test, pred_probs))
# Export the AUC score to the analyst
comp.export_analyst()
auc = comp.run()
Similarly, the AUC from the XORBoost model is 0.986 while the one from the XGBoost model is 0.982. These numbers show that the secretly trained Inpher’s XORBoost model gives the same prediction quality as the official XGBoost library.
Required Resources
Training the XORBoost model is much more resource-intensive than prediction. As such, we only report the resources required to fit this XORBoost model on the training dataset:
-
Training dataset size: 39’753 samples, 29 features
-
Total running time: 2h33min
-
Peak RAM usage (per player): 2.1 GB
-
Generated masking triplets: 52.3 GB
Conclusion
From the results above, we conclude that XORBoost allows training models of similar quality as the XGboost library. This is done while keeping all inputs and intermediary results secret. Moreover, no restriction is made on how the data is distributed amongst the parties, making XORBoost widely applicable. While the resources required to train such a model are larger than the plaintext equivalent, the total runtime and memory requirements remain reasonable.
We are excited about the direction of the project. In particular, we are working on using XORBoost for use cases in financial services (like anti-money laundering, fraud detection and credit risk modelling) and healthcare (such as early detection of diseases).
Are you interested in trying out the XORBoost notebook?
Additionally, if you have a use case in mind that you would like to try out with XORBoost, reach out to us at [email protected]