Authors:
Generative AI represents one of the fastest adoption rates ever of a technology by enterprises, with almost 80% of companies reporting that they get significant value from gen AI. Of course, AI systems are only as smart as their data. Many companies are looking for models that can provide reliable, specialized responses based on enterprise-specific data. Retrieval-augmented generation, or RAG can be an effective solution to fine-tune a gen AI service to a company’s specific needs.
Yet data privacy is a stumbling block for RAG, as for gen AI overall. Companies that implement privacy-preserving RAG systems are leading the way to the future of enterprise gen AI.
What Is RAG?
Chatbot development usually begins with API-accessible large language models (LLMs) already trained on general data. Retrieval-augmented generation (RAG) is a way to introduce new data to the LLM in order to advance user experience by leveraging key organizational content that will result in an improved prompt response that is specific to the business, department and/or role.
With RAG, the LLM’s responses are grounded in authoritative content retrieved from external, enterprise-specific datasets. A company’s technical manuals, policy documents, logs, and more can all become knowledge bases that enhance LLMs. RAG systems can be used to create any number of niche assistants that support employees and customers: for example, to enhance developer productivity, facilitate customer service, provide personalized recommendations, or ensure compliance.
How Does RAG Work?
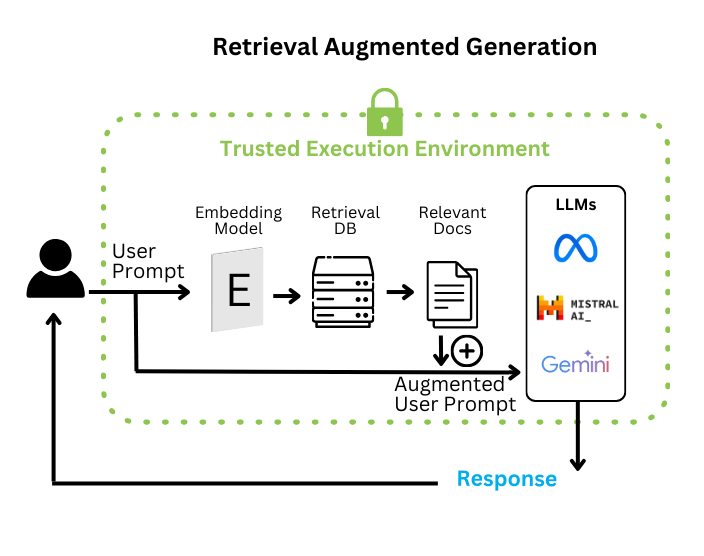
As indicated by its name, RAG systems combine information retrieval with text generation.
The goal of the retrieval stage is to match the user’s prompt with the most relevant information from a knowledge base. The original prompt is sent to the embedding model, which converts the prompt to a numerical format (called embedding), or vector. This can be compared to the vectors (embeddings) in the index of a knowledge base. The most relevant matches and their related data are retrieved.
In the text generation stage, retrieved data is converted into human language and added to the original prompt to augment the prompt with the most relevant context from the knowledge base (hence Retrieval Augmented Generation). The LLM creates a response to the user’s prompt, using pre-trained knowledge and retrieved data, possibly citing sources identified by the embedding model.
Flexibility is a notable benefit of RAG system architecture. The three basic components – the dataset, the retrieval module, and the LLM – can be updated or swapped out without requiring any adjustments (such as retraining) to the entire system.
Benefits of RAG
For companies, RAG offers a number of advantages over using a general LLM model or building a specialized model.
Cost Effective
Most organizations are predicted to buy, not build, gen AI services. Yet even retraining LLMs for enterprise-specific purposes is financially and computationally expensive. RAG systems are a cost-effective alternative to fine-tuning a model for enterprise-specific needs.
Reliable
In fast evolving domains, LLMs trained on a certain body of data are soon out of date. As a means of addressing this, continuously updating the model’s parameters and training it on new data is costly and time-consuming. With RAG, an LLM can reason over information resources that are updated as needed (for example, the latest version of a legal document).
Moreover, gen AI services have become notorious for hallucinations. These incorrect answers make LLMs less reliable – and as a result, less usable for companies. Because they are grounded in reliable content, RAG models have been shown to have fewer hallucinations.
Trustworthy
A RAG system has been compared to an open-book test, where the model looks for answers in a specific resource. Unlike other LLMs, this also means that the model’s output can be verified by checking the information sources. In other words, RAG makes gen AI more transparent and trustworthy.
Risks of RAG
There is extensive research about the data privacy risks of LLMs. RAG systems, too, can be susceptible to attacks and data breaches. One study shows that RAG systems are highly vulnerable to prompt extraction attacks, with a considerable quantity of sensitive retrieval data being revealed.
In many cases, the data that companies want to leverage with LLMs is sensitive. The CISCO 2024 Data Privacy Benchmark Study shows that 48% of organizations are already entering non-public company information into gen AI apps, while 69% are concerned that gen AI could hurt company’s legal rights and intellectual property. If RAG systems are not sufficiently secured, companies could face legal consequences and loss of customer trust, as well as fines.
Companies are constrained by current regulations around user privacy such as the EU’s GDPR, California’s CCPA, and HIPAA for U.S. health information. As the gen AI landscape evolves, privacy laws and regulations will too – such as the EU AI Act, which was recently approved by European lawmakers. Companies need to be prepared to comply with evolving regulations.
RAG with Confidence
A powerful security framework, confidential computing is designed to protect sensitive data while in use, within applications, servers, or cloud environments. Confidential computing has the potential to secure the entire RAG inference process.
During computation, confidential computing isolates data in a hardware-based trusted execution environment (TEE). The TEE is a secure enclave where sensitive computations can occur, employing hardware-based mechanisms to prevent unauthorized access and tampering. TEEs can be processor-level or VM (virtual machine)-level; virtualization overcomes some of the compatibility and application development challenges present for processor-level TEEs.
Key features of confidential computing include secure boot (the system boots into a defined and trusted configuration), curtained memory (memory that cannot be accessed by other OS processes), sealed storage (software keeps cryptographically secure secrets), secure I/O (prevents keystroke logger attacks) and integrity measurements (computing hashes and fingerprints of executable code, configuration data and other system state information). An example of this can be found in a recent blog post by our partner Nvidia.
In a RAG system, confidential computing secures the user prompt, knowledge base, embedding model, and LLM in a TEE.
The Future of Enterprise Gen AI
Enterprises can harness the power of gen AI by using RAG systems to achieve cost-effective, reliable, and trustworthy results. Given the importance of data privacy, RAG systems implemented with confidential computing represent the future of gen AI for enterprises.
For more information about Inpher’s SecurAI solution for privacy-preserving use of LLMs, including RAG systems, view our quick demo video: