Authors:
Even if you’ve never heard of Federated Learning (FL) before, it is likely that your data is being processed and analyzed using this technique right now. Look around the room – at the laptop or mobile phone, you are currently using to read this blog, at the home speaker in your living room, your wearables that track your steps and heart rate.
With the advent of the Internet of Things (IoT) and smartphones, companies are at the disposal of millions of devices and their local data. In order to collect behavioral data to train predictive models and to push updates onto the millions of individual devices, tech companies have developed FL to compute on federated datasets. This allows the central server to learn from, and communicate with, a large number of devices without uptaking raw personal data.
But many consumers use phones and IoT devices that rely on FL every day without knowing what it is. This means that the novelty of FL is shielding scrutiny on its inherent—and new—security vulnerabilities coming to light. While FL is a useful technique to aggregate information held by millions of compute nodes, it needs an extra layer of privacy-enhancing technology to ensure there is no leakage of personal information through “model parameters” that expose sensitive inferences at the individual level.
In this part 1 of the two-part blog series, we survey emerging threats to FL and discuss various privacy attacks. In part 2, we will examine how two advanced cryptographic techniques, Fully Homomorphic Encryption (FHE) and Secure Multi-Party Computation (MPC), may be critical to an institution’s ability to anonymize data and fully meet the obligations of various data protection regimes such as the EU General Data Protection Regulation (GDPR).
HOW FEDERATED LEARNING WORKS
Federated Learning (FL) solves a key problem: to allow machine-learning (ML) models to scale predictions on millions of edge devices, such as mobile phones, without collecting raw personal identifiers. It enables multiple parties to jointly train a shared model while keeping the device data local. This decentralized approach to training a model eliminates the need for large, expensive centralized storage and a high-bandwidth network.
FL is relied upon to run local computations on the device data and has the capacity to process large volumes of compute nodes (edge devices) communicating with a central server. In other words, FL enables a decentralized framework for machine-learning by computing on local data that is distributed across millions of devices.
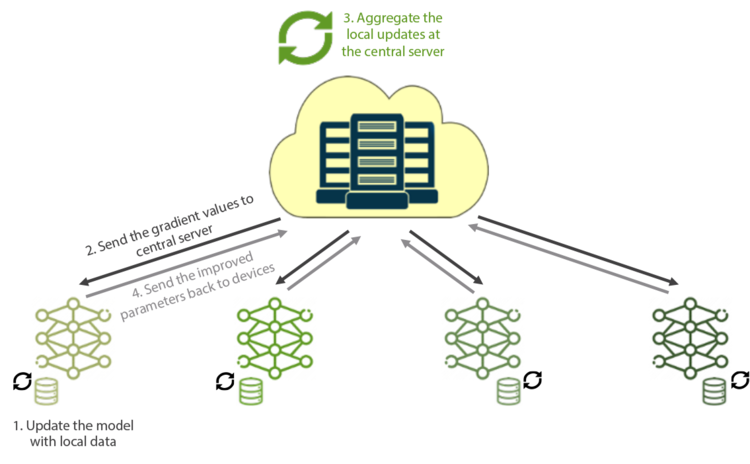
Functionally, the process works like this:
-
Train the models on the devices by using local data
In the first step, the current model is downloaded from the central server to the devices. Once downloaded, the model is updated using the device’s local data for a specific number of iterations. FL relies on local devices’ computation power to process the data.
-
Send local updates (gradient data) to the central server
Next, the gradient values from the locally trained model on the devices are sent to the central server. Since the training is performed on the devices, the technique is built to accommodate millions of devices with minimum latencies or overheads, as the compute nodes need not communicate with each other—only with the central server.
-
Aggregate all the local updates at the central server
Once the devices send local updates to the central server, the server’s task is to aggregate the model parameters into a global model. Algorithms such as FedAvg or FedSVD make it easier to use functions such as Stochastic Gradient Descent in an FL environment.
-
Broadcast the improved parameters back to the devices
With the updated parameters, devices can access a more accurate model than they could have built using their local data. A new party can join or leave at any time without halting the training of the model, as it’s not reliant on any specific data.
The above four steps iterate multiple times to obtain a good model.
While the initial goal for FL was to decouple the need to do ML with the need to store the data on the cloud, the approach has also been suggested to solve data-privacy problems since raw, personal data never leaves the local devices.
PRIVACY RISKS WITH FEDERATED LEARNING
There is an increasing interest in the FL approach beyond hyperscalers, especially in regulated industries such as healthcare and financial services. However, it’s not widely known that FL by itself doesn’t protect data privacy.
Recent studies demonstrate that FL may not always provide sufficient privacy guarantees, as communicating model updates throughout the training process can nonetheless reveal sensitive information; even incur deep leakage, either to a third-party or to the central server. For instance, as shown by Aono et al. in 2018, even a small portion of original gradients may reveal information about local data.
Three primary attacks can expose sensitive information without ever accessing the local devices’ data:
-
Membership Inference Attacks:
With Membership inference attacks, adversaries can exploit privacy leakage about individual data records in FL training. The membership inference attack can determine if the record was in the model’s training dataset. An adversary builds a shadow model to create a dataset that is familiar to the original dataset. If the (shadow) model’s prediction has high confidence values, it is similar to the original dataset.
Inference attacks exploit privacy leakage that occurs during gradient sharing in FL training. Model updates can leak extra information about the unintended features of participants’ training data to the adversarial participants, as deep learning models appear to internally recognize many features of the data that are not apparently related to the main tasks.
-
Model Poisoning Attacks:
Model poisoning attacks affect model performance without being noticed. One could deploy a flipping attack by manipulating the model update or a more complex target attack that can leverage global ML models to do what they want. This blog post details more on model poisoning attacks.
-
Model Inversion Attacks:
If an adversary can query the model enough times, they can reconstruct the clear-text model using an Equation solving attack. The adversary can learn about the distribution of the training data from other participating devices. The adversary can also save the snapshot of the FL model parameters, and conduct property inference by exploiting the difference between the consecutive snapshots, which is equal to the aggregated updates from all participants less the adversary. The main reason is that the gradients are derived from the participants’ private data.
These attacks can happen either at the centralized server or at one of the participating devices, making it harder to identify vulnerabilities. Here are few examples to specifically look out for:
Vulnerabilities at local devices:
-
FL produces hyper-personalized model responses from the local updates of individual devices. This makes FL vulnerable to various model inversion and inference attacks on the model parameters.
-
One of the most common assumptions made in machine learning is that the given data points are independent and identically distributed (IDD) random variables. However, a malicious participant can inject non-IID data to execute poisoning attacks, leading to participants’ local updates varying vastly, thereby affecting global model accuracy.
-
Local training requires labeled data which are often difficult to produce in most cases. Data science teams are tackling this by designing data pipelines that implicitly capture labels. However, a malicious device can observe the model parameters and updates to infer a significant amount of private personal information such as class representatives, membership, and properties associated with a subset of the training data. Even worse, an attacker can infer labels from the shared gradients and recover the original training samples without requiring any prior knowledge about the training set.
Vulnerabilities at central server:
-
FL relies on a central server to aggregate the gradient values making it an easier target for malicious attack. Once successfully hacked, adversary actors can deploy a wide range of attacks that can reveal privacy-sensitive information from millions of connected devices.
-
A malicious or a hacked central server can track the devices and their associated gradient values. Hence by exploiting the confidence could exploit the confidence value revealed along with predictions to reconstruct an edge device’s training data by using a model inversion attack.
-
A recent study has demonstrated that a compromised central server can reveal sensitive information through reconstruction attacks during gradient client updates and k-nearest neighbor when it explicitly stores the feature value.
-
Recent work in NeurIPS 2019 showed how a malicious server could completely steal the training data from gradients in just a few iterations using a membership inference attack.
To remedy these vulnerabilities, the server can use other privacy-enhancing techniques like FHE or MPC to power a secure aggregation and prevent privacy leakage or model inversion attacks that may reveal personal data from individual devices.
MPC would be applicable in a multi-party ML development system that purports to train a shared model on multiple participating entities’ datasets procured with FL. Using MPC would also eliminate the vulnerability at the central server as it requires multiple servers for secure aggregation.
Part II of this blog series on the privacy risks of Federated Learning will discuss this solution in more technical detail.
CONCLUSION
FL offers a foundational structure for a lightweight privacy-preserving computation of many nodes. Still, expert sources overwhelmingly agree [1, 2, 3, 4, 5, 6, 7] that further measures are necessary to fully protect the underlying device data. FL’s increasing vulnerabilities to model inversion and inference attacks can happen both from within the server and from other participants who can observe the global model parameters, thereby raising concerns under the GDPR. The GDPR protects data subjects against algorithmic profiling and sensitive inferences. ML systems exposed to these threats can be sanctioned under the GDPR—whether or not regulators accept the Royal Society’s conceptual recommendation to classify ML models as “personal data.” There is abundant academic and applied research on the vulnerabilities of FL that point to a need for FL systems to be supplemented by other cryptographic privacy safeguards.
In the next blog, we will discuss how two popular privacy-enhancing techniques, FHE and MPC, powers secure aggregation in FL and prevent personal data from leaking.